This interview provides a behind-the-scenes look at the research contributing to an upcoming report. The blog post reflects the perspectives and opinions of ICTC’s analysts rather than those of the organization.

Photo by Aditya Chinchure on Unsplash
The impact of Artificial Intelligence (AI) on the future of Canada and the world is much debated. In February 2020, the Information and Communications Technology Council (ICTC) will release a study on Canada’s AI ecosystem. ICTC Research and Policy Analyst Faun Rice interviewed the study’s authors, Ryan McLaughlin and Trevor Quan, to learn about their research process and findings. In this interview, the team gives a preview of the study with a discussion of the importance of conceptually separating AI from robotics, the relationship between AI and the recession, and upcoming ethical issues in AI research, development, and implementation in Canada.
Faun: Starting off with the basics, what are some of the main research questions that shaped this study?
Trevor: The central goal was to map out Canada’s AI ecosystem, but that’s, of course, a big topic. We examined AI activity by region, the socioeconomic impacts of AI in Canada, areas of opportunity for the use of AI in different strategic sectors, and the ethical challenges in the use of AI. To start off with, we had to frame “what is AI” so that we were talking about the same thing. It can vary by context and industry. So we began by scoping out a definitional framework.
Ryan: Trevor was responsible for a lot of the qualitative work and context, so he looked at the history, what the actual technology is, what’s going on with the ethics, and where AI is headed. My piece focused on labour-force impacts.
Trevor: We made sure that we were capturing different elements of the economy so that we weren’t just looking at high-tech software but also at a large variety of different sub-sectors across the economy. From there, we looked at different skills and the impact of AI on them for the future.
Ryan: We used a methodology that I think is pretty interesting. While labour-force data came in part from Statistics Canada, another source was O*NET. This data is from the US Department of Labor. It includes every occupation code in the US, which they call SOC codes for Standard Occupational Classifications. For each SOC, there are 160 different skills, which are rated by the importance of the skill to that job and the difficulty level of the skill. For example, as an economist, I do a lot of math and it’s of high importance to my job, but it’s not highly complex math, so it’s of a lower skill level than what a professional mathematician might be doing. So, there are two ratings there-importance to the job, first, and difficulty, second.
For every occupation, you can have a composite score based on what portion of the essential skills can be augmented by AI, taking both importance and difficulty into account. So, while that score for single occupation is pretty hard to interpret, what gives it meaning is the relative rank of jobs. In my case, some of the findings were intuitive, whereas others revealed some things I did not expect.
Faun: That’s interesting, and we’ll get back to that list. First, I want to ask a bit more about the methodology. Could you talk a little about the process of assigning AI-appropriateness to particular skills? Did you run into any issues in that ranking?
Ryan: One thing we had to be really clear on was separating robotics from AI because we weren’t trying to create a ranking of jobs vulnerable to automation writ large.
Trevor: Right, isolating the impact of AI on a particular skill was an interesting challenge, especially since a lot of existing labour-force research tracks larger industry trends rather than trying to pinpoint the impact of AI.
Faun: Here’s a question. In your effort to be clear about isolating AI impacts, rather than creating an automation ranking, you mentioned trying to exclude robotics. What other things did you have to be really clear about excluding?
Ryan: While there are lots of overlaps between robotics, AI, and other technologies, there are some skills like “dexterity,” which are physical traits. So that’s the kind of thing we would consider a robotics question, not really AI, and give it a lower score. But then there are other types of efficiencies, like using computers for cashiers, which are almost procedural or social automation-and those too might not necessarily be employing AI. People tend to mix a lot of those categories together, and that’s not really what we were aiming for.
Faun: Returning to the job ranking, what types of patterns did you see?
Ryan: Using the data we had available, we were able to link things like demographic characteristics to each job. In so doing, we found that jobs with high rankings for AI suitability are disproportionately staffed by immigrants, women, and people who are either really young or really old, not so much middle-aged. That’s one reason we believe AI creates a need for many different demographic groups to upskill.
Trevor: There are definitely some policy implications if the impact is going to be disproportionately borne by certain groups, and certainly more vulnerable groups to begin with. I think it goes along with ideas about subsidized or targeted upskilling, education assistance-that kind of thing. And that’s an international conversation. We were working on the Canadian context, but our ranking with regard to AI suitability and the overlaps with automation were largely aligned with other academic findings around the world.[1]
Faun: Can you give an example of a study that found some parallels?
Trevor: Osborne and Frey did something similar looking at the impact of “computerisation,” not really AI specifically, but they also used a machine learning model to create the ranking.
Ryan: I don’t think that relying on qualitative feedback from key informants to do the ranking as we did is any less effective, but they got a lot of media play for having an AI do part of the work. It was a bit of humorous irony. The other neat thing that we saw in the data was a relationship between employment and the recession during 2007–2008.
Faun: I was going to ask about that. What made you choose to include a discussion of the recession in a report on AI?
Ryan: It was very clear that something was going on, as shown in charts like Figure 6 in the report. We split the ranked occupations at the median, so the top half was the most AI-suitable, and then looked at their labour-market stats over time. It’s very clear with so many different occupations that something odd happens around this time, around the recession. Occupations grow and grow, and then in 2007, it flattens out.
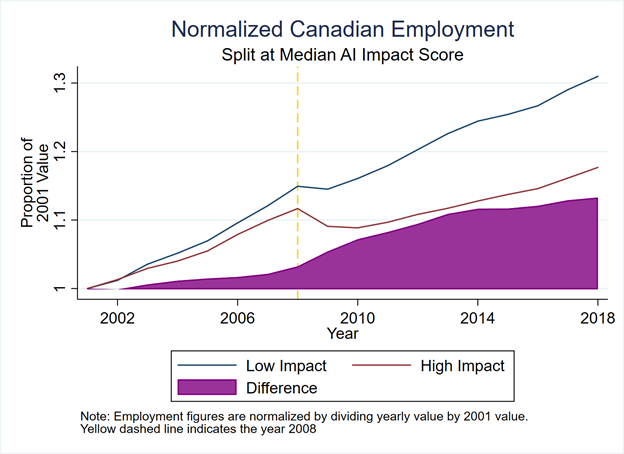
Source: ICTC, 2020
So, during the recession, a bunch of people were laid off, which we know, but then a bunch of these occupations fail to grow substantively afterwards, even during the economic recovery. Our theory is that employers turned to new maturing software solutions being offered by vendors because they felt pressured by economic challenges. I think it also matches the literature and hypotheses of different researchers who say that times of recession create a pivot from high-staffing levels to greater investments into capital funding for efficiencies-and it’s around the same time as AI-related or low-level AI solutions happened to be reaching maturity.
Faun: What do you mean by “low level”?
Ryan: I think that a lot of the AI fear is overblown, in part because of the distinction between what people think of as general artificial intelligence and narrow AI. The first part of the report gets into all this definitional stuff, but to summarize what I mean for the purposes of this interview, low-level AI can be things like shortcuts, automating some workflows, and also introducing more work, like using AI to work on predictive analytics with big data that didn’t exist before.
Trevor: There’s also something to be said about humans slowly sorting themselves out into new occupations. Ryan was talking about certain jobs flattening out long-term even when the economy is growing again. But if the unemployment rate isn’t bottoming out, then those people who were laid off during the recession are likely shifting into other types of jobs, or employment rates wouldn’t have recovered.
Ryan: Right, the US is seen as more “innovative” than Canada, and they have basically all-time low unemployment rates at the moment. So it’s hard to give credence to any argument saying that labour is obsolete.
Faun: You mentioned before that many of the most AI-suitable skills you found are used in jobs that are lower-income, and you started to talk about the policy implications around this. Was there any job that had a high ranking that came way out of the left field and surprised you?
Trevor: Yes, we tried to consider wages in our analysis because there are some jobs that would be easy for an AI to do, but the wages are so low that it isn’t really costing employers much to have humans doing those jobs currently. On the other hand, jobs like financial analysts, some law-related roles, or something like medical imaging, where you have a lot of AI-suitable skills that are very costly. So that’s something we thought about. But it’s also important to think about professional and local contexts-whether more powerful industry associations or regulations will have an impact on speed and style of AI-introduction, or whether you’ll see different effects in regions with different minimum wages.
Faun: You mentioned that interesting bit about people changing jobs rather than facing unemployment. Is there any study that takes a look at career changes as a result of any kind of automation?
Ryan: That’s beyond the scope of this project, but it’s an interesting proposition. Companies like LinkedIn might know that if people are self-reporting accurately. Typically, independent researchers wouldn’t be able to know because all national surveys here are anonymized. You can’t usually track people from category to category. You just get snapshots without identifiers.
Trevor: When I was completing interviews for this project, it’s natural to ask what will happen in the future of different jobs. But for a lot of the people working in AI for a really long time, most of them were reluctant to guess or unsure of how to accurately predict these trends. So impacts will be visible over a long period of time and difficult to isolate.
Faun: In your opinions, what are some of the most interesting areas where we might see the impact? If you don’t mind engaging in guesswork, informally.
Trevor: Programs that can find patterns in big datasets are really interesting. Whether we’re getting really high-quality analytics from bigger datasets, or if more data simply comes at a greater cost of computing power is an important question though. There may be questions of diminishing returns in the future.[2]
Ryan: The other problem is that correlation is not causation, which is a problem for “blind” or naïve machine learning. One may naively assume that if you just have enough data and you run enough regressions, you’re going to find actual causal relationships. Instead, you will probably just be finding a lot of correlations. When you try to act on these correlations, they break down. For instance, imagine noticing that it is often sunny when people are at the beach in swimsuits so, brilliantly, to improve the rainy Vancouver weather, you send a crowd of people in swimsuits to the beach. But you have confused the direction of causality in the correlation. When you “act on” the correlation, it breaks down and the rain continues to fall on the beachgoers. Besides this, we don’t have data on everything, and we never will. Some things are just inherently unmeasurable, and those unmeasurable things can still be driving outcomes.
Faun: Is there anything aside from big data that you think will be a clear AI impact in the coming years?
Trevor: I come from a bit more of the social side, and I think you’re going to be seeing a lot more in terms of algorithmic bias and the way that fits into AI decision-making. Hopefully, we’ll see a lot of learning there. I mean, you’re taking datasets that reflect current and historical inequalities and then using them to try and predict things for the future. I find it quite troubling when some of the public believes that AI and algorithms are entirely neutral or unbiased.
Ryan: Related to this idea of finding an only correlation, it’s going to get additionally troubling if the race is correlated with something like recidivism, but the causal factor is some hard-to-measure or omitted variable. Your model relies on race as the statistically significant variable because perhaps it is serving as a proxy for hard-to-measure poverty, or lack of opportunity, or discrimination. In the model, although race may not be the per se causal factor, it may still be predictive since it is correlated with other variables. Therefore, it’s morally difficult to know what to do.
Faun: I think the example you bring up in the report is the Amazon resume case, which by now is pretty well-known.[3]
Trevor: That’s right, a pretty current example of the issue of training data and what negative patterns it might reinforce. It’s nearly always a reflection of the current status quo and who a company like Amazon is already inclined to hire and promote.
Faun: You’re reminding me of a conversation I had about GIS data classifications-it’s someone’s job to say, “What do we call a forest?” and define the necessary and sufficient conditions for these basic geographical categories. While a program might then apply that rule far more consistently than a human, it’s still based on the human’s particular viewpoint as to the difference between a glade and a clearing, or a good and bad CV. We started this interview by talking about the skills that still need to be performed by humans and it’s apparent that people attribute categories and the relative value of those categories, for better or for worse, right?
Ryan: Someone always has to provide the training data.
Trevor: Which is not just about what you choose, but also what you omit. We can try to be as objective as possible, but there’s still unconscious selection at work.
Ryan: It’s tied back a little to what I was saying earlier about the former study of jobs vulnerable to computerization that used a machine-learning model to assign the scores to each job. We like to think, we’re “subjective” but the machine will be “neutral,” but it doesn’t know anything that we don’t know. So you’re feeding your biases to the “objective” machine, and you really have no choice but to do that.
Trevor: I think that’s the biggest area where we’re seeing the impact of AI right now. People are starting to see where those problems will emerge. The labour-market impacts, we might be seeing those, but the full impact is going to take a long time to really be visible, I think.
Ryan: It’s tough to know when the technology will really mature into particular applications and then, from there, how quickly it will be implemented. Certainly, while people may have changed professions, we’re not yet seeing a huge impact on the overall unemployment rate, so the lesson from our report is mostly about “skills not jobs,” as the current mantra goes.
[1] See, for example: https://thenextweb.com/contributors/2018/04/02/automation-leaving-women-minorities-behind/ ; https://www.mckinsey.com/business-functions/mckinsey-digital/our-insights/how-automation-could-affect-employment-for-women-in-the-united-kingdom-and-minorities-in-the-united-states; https://qz.com/1167017/robots-automation-and-ai-in-the-workplace-will-widen-pay-gap-for-women-and-minorities/
[2] For further reading, see: https://www.technologyreview.com/s/614700/the-computing-power-needed-to-train-ai-is-now-rising-seven-times-faster-than-ever-before/ ; https://allegro.ai/blog/quantifying-diminishing-returns/ ; https://towardsdatascience.com/is-deep-learning-already-hitting-its-limitations-c81826082ac3 ; https://www.technologyreview.com/s/612768/we-analyzed-16625-papers-to-figure-out-where-ai-is-headed-next/
[3] In 2015, Amazon realized its experimental hiring tool that used artificial intelligence was not rating candidates for software developer jobs and other technical posts in a gender-neutral way.