Artificial Intelligence (AI) is advancing in the private sector, the public sector, and computer science departments around the world. However, transforming AI research into a working application for your average business is easier said than done. In this conversation, Anna Koop, Alberta Machine Intelligence Institute (Amii) Managing Director of Applied Science, speaks with ICTC’s Faun Rice about Amii, its place in Canada, and its team. In addition, Anna and Faun talk about the challenges that businesses face in applying AI solutions, as well as the degree to which researchers in academia are responsible for considering the social impact and eventual application of their work.
About Amii: Founded in 2002, based in Edmonton, and affiliated with the University of Alberta, Amii is one of Canada’s three artificial intelligence hubs. Amii has drawn partners such as DeepMind (Google) to Edmonton. The institute pursues fundamental research, business partnerships, training programs, and talent-matching. The work at Amii has contributed to famous achievements in computing science, such as AlphaGo, the first program capable of professionally playing Go (traditionally viewed as the most challenging classic game for artificial intelligence). Amii’s researchers into AI and gaming have also created the first program to outplay professional no-limit Texas Hold’em players, while the robotics lab has made significant advances in the use of intelligent prosthetics.
Faun: Thank you very much for joining me today! I’m from Edmonton and look forward to learning a bit more about the work going on at my former university. Let’s start by talking a bit about Amii. Can you give us a taste of its origin story?
Anna: Absolutely. As the not-for-profit organization it is today, funded as part of the CIFAR Pan-Canadian Artificial Intelligence Strategy, Amii was born out of a research lab at the University of Alberta. The Alberta Innovates Centre for Machine Learning existed way back in the Heritage Fund days of the early 2000s. We had a really strong research group in AI for games. When they were putting together the Centre of Excellence plans, a group of professors in the computing science department got together to propose a Centre for Machine Learning Excellence. Through that grant and that centre, we grabbed some amazing talent. We managed to snag Richard Sutton, who’s the major leading light in reinforcement learning, Dale Schuurmans, and Michael Bowling. So we built up this strong cohort of researchers — and this was during one of the AI slumps when AI was still thought of as “pseudo-science.” It’s funny participating in this field because it goes through real ebbs and flows.
Then, when the deep learning revolution hit — this latest wave of super-high interest in AI and machine learning — we actually had this really strong cohort of professors doing phenomenal research, attracting really amazing grad students. When the CIFAR Pan-Canadian AI Strategy was announced, it was natural for Edmonton to be one of those centres of excellence because Montreal and Toronto had some of the founders of the deep learning revolution, and we had this really strong cohort across the breadth of machine learning and especially in reinforcement learning.

Faun: If we can take a quick sidebar here, would you mind giving your elevator pitch version of what “reinforcement learning” means as a part of machine learning?
Anna: Reinforcement learning is specifically learning by interacting with an environment. That’s a high-level definition with lots of caveats.
AI is a big field, and it encompasses all the things we do to try to make computers behave more intelligently, or to do things that don’t have to be directly programmed in. In other words, we don’t want to tell it the path through every maze; we want it to be able to find a path through any maze. With machine learning, you’re specifically using data for a computing agent to learn from. Data can be past experience or labelled examples, and the machine learning piece is figuring out the connection between that and the problem at hand.
Then within machine learning, there are three subfields. Supervised learning is what most people think of when they think of machine learning. You feed in an image, and you get told there’s a cat in the image. You’re given an example, and you’re told the label or the value or the prediction about that specific example. In order to train those systems, you actually have to have a really big dataset of those labelled examples.
Unsupervised learning is looking for patterns in a more general sense. So, how do we take all the posts on Twitter and categorize them? We could look at that as a supervised learning task if we’re saying, “Is this about sports? Is this about news?” Or, we could look at it as, “What patterns emerged, how many are there, and what do they consist of?”
Finally, reinforcement learning adds the time dimension: a computing agent is interacting with the world, choosing actions, and getting observations back. Most of the time, there are also special reward signals. So, we don’t tell the agent what it needs to do, but we do say “Good job!” or “Bad job!” It’s the computing agent’s job to figure out what that means in terms of, “Did I choose the right actions? Is that why I got a ‘good job’ or did I just get a ‘good job’ because it’s a nice day and everybody’s happy?”
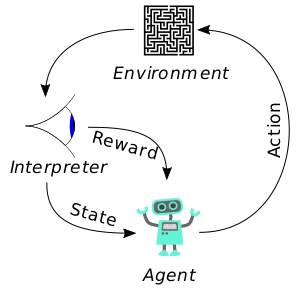
A simple representation of a reinforcement learning system (licensed under CC0 1.0).
Faun: That’s really helpful, thank you. Back to Amii, could you talk a little about what sets you apart? What would you say the core difference is between organizations like Amii, MILA, and the Vector Institute?
Anna: Toronto has the Vector Institute, led by Geoffrey Hinton. Their real core is deep learning, and being in a major business centre, they have a lot industry supporting fundamental research on a big scale. MILA’s research excellence is a combination of deep learning and reinforcement learning, and they have some talent-matching programs like ours. Then Amii has a lot of breadth. We cover a lot of ground with the expertise in our faculty, including reinforcement learning, and we’re a very collegial group. Students who interact with us are always flabbergasted when our Fellows are readily available to chat with them at conferences.
We also have a very “boots on the ground” approach to working with industry in Alberta. Throughout our history, we’ve been concerned with how we can help industry and how we can help diversify Alberta’s economy. A lot of new businesses know that they should care about machine learning but oftentimes have no idea where to start. It’s really expensive to get started if you come at it from a perspective of, “OK, I need to hire a PhD graduate with machine learning expertise” and somehow turn that into business value real quick. It’s a massive change! A lot of companies are still struggling to digitize data and then actually look at it. So to go the next step and use predictive models or more advanced techniques is kind of overwhelming.
Faun: Do you work only with businesses who are totally new to AI?
Anna: Amii now has what we call the “machine learning adoption spectrum.” We look at where a company is on this readiness scale, from “just heard of machine learning” to “I know it’s important but don’t know what to do with it or what the first steps should be,” all the way up to companies like DeepMind, where you have an advanced elite research team that is working on problems and pushing boundaries. We have a range of services to cover the entire breadth of machine learning readiness.
On the more advanced end, we rely heavily on our research Fellows. On the introductory end, we have a heavy emphasis on education, and I’m especially proud of the program we’ve built out. The Machine Learning Technician I Certificate is designed for people with a somewhat technical background but who are new to machine learning, like petroleum engineers or data analysts from other fields. The machine learning technician course gets you up and running in a responsible, thoughtful implementation of machine learning models. It’s really needed because while there’s lots of tutorials online, and you can learn all kinds of things on your own, there are particular issues that we see over and over again that arise for companies trying to implement ML. Our early stage educational materials address those common issues: What are the things we’ve seen that really trip companies up, and how can we equip them to not make those mistakes? Then we also have a complement to the technician course for the management and executive level called “AI for Strategy and Management.” It’s what you need to know about machine learning in order to make informed decisions. You don’t need to know how to program neural networks. You don’t even have to know how to write Python code in any sense. But you do need to understand what models are. What is this thing we’re building? What do we need to build it? How does it relate to business value? And how do I tie it back and make sure everything’s on the right track?
Technical and Executive training programs offered by Amii. From https://www.amii.ca/training/, accessed November 17, 2020.
Then in addition to those two programs, we have three other major arms: Coaching Services, where we pair companies up with scientists and project manager teams to, depending where you are on the adoption spectrum — push your first proof of concept forward or take what you’re doing and push it to the next level. Then Talent Advisement is the third arm. That first hire can be really difficult. It’s difficult to access talent these days because it’s in high demand and the hype is high right now. It’s also difficult to know what talent you need, especially if you are not already a machine learning shop. Then how do you distinguish good candidates? So we provide a kind of suite of services to help. Then the fourth arm is our core, which is Advanced Research.
Faun: Before we move on, let’s talk a bit about Advanced Research — what is your own background academically and your area of interest in AI?
Anna: My research background is reinforcement learning. I got pulled into the field listening to Rich Sutton, Dale Schuurmans, and Michael Bowling talk about the amazing, interesting question “What does it even mean to be intelligent?” and “What is different about biological systems and artificial systems?” A lot of my more recent work is on learning within changing environments. When we think of the real world, if I walk outside today, I have to interact differently with the environment than I did four months ago or six months ago because the environment is constantly changing. We’re really good at adapting to changes, but we don’t know how that works. So this is kind of the undercurrent in all my research: how do we adapt after all?
Finally, with Amii, I’m the managing director of the Applied Science Team, which means I get to work with the scientists who are directly interacting with client companies and our partners. A lot of the work that the science team has done is around defining the difference between a research problem and an industry problem. One of the two primary differences that we’ve highlighted between the academic approach and industry approach is this: For one, in the academic world, you’re looking for something people haven’t done before. You’re looking for gaps in understanding and trying to fill those gaps. Most of the time in the business world, you’re looking for something that adds business value, and the gaps are not the most comfortable place to be. You can do some really innovative things in there, but first, start with known tools, right? Tried-and-tested things. There’s a ton of value still to get out of those. Even the most basic machine learning techniques can still unlock so much potential.
I think of the science team as doing this shift from academic goals to industry goals: How do we use all the tools and great stuff we’re developing academically and actually put them in the hands of people doing business day by day.
Faun: That’s a great overview and very relevant to my next question. We’re talking about industry applications of AI, so let’s pivot to a recent set of events. As I understand it, NeurIPS, one of the leading AI conferences in Canada, recently added a requirement to include a social impact statement in conference proposals, and that kind of sparked a bit of a conversation in the discipline. So, blank slate, what has your experience been with the inclusion of social impact assessments in publishing and conferences?

Reddit r/Machine Learning Discussion of NeurIPS 2020 Impact Statement. Screen capture taken November 17, 2020.
Anna: Yeah, it’s a really thorny issue, actually. And I am 100 percent on board. We have a really serious responsibility to understand how the technologies we develop are being used and the impact they’re having in the world. On the one hand, I think the person who “invented electricity” — well, no one person invented electricity — but my point is that Thomas Edison is not responsible for every electrical device that comes after him. On the other hand, the models we release on the world have impacts and it’s just kind of a basic human-decency thing to understand the impact your actions are having. One of the ways that has translated into academic publishing is now several conferences have impact statements. You have to ask, “What are the ethical implications of your work?”
For a long time, we’ve gotten away with not having to worry about the ethical implications in some sense: there are very strict ethical guidelines for experiments on humans or animals in the biological sciences. That aspect hasn’t been as relevant in computing science because it’s just us sitting at our computers doing our thing. But now that technology is being adopted really widely, there are a lot of unintended consequences as well as a lot of misapplications.
I think we have responsibilities on a couple of fronts. First, I think we should know how the technology is impacting others. So deep fakes, for example, come out of a lot of totally legitimate research into how we parse images and how we fill in gaps. And, yes, people can then take that technology and turn it into, “How can I put words in someone’s mouth, or how can I put people in compromising videos?” I’m not of the school that we shouldn’t explore those technologies because they have potentially bad outputs. But I think we need to make sure people know about the technology and how it works, which is one of the things I love about Amii’s education programs: we have to focus on levelling the playing field, giving everyone we can an understanding of this because we’re all impacted.
I’m on the fence with the impact statement for a couple of reasons, mostly because most of them that I’ve read are not that impactful. Even with some of my work, I’ve struggled. I’m doing experiments on an incomprehensibly small environment. I’ve got five situations, and the agent has to choose between two actions. It bears no resemblance to any real thing because I’m testing out concepts. On the other hand, my body of research is about learning in changing environments. That ultimately does have a significant impact on real-world applications because the real world is changing. It’s a tough question, though. What are the ethical implications of one plus one equals two, right? That definitely gets used in a lot of situations, but there’s a lot of steps between the math and the application. On the other hand, I’m sure we rely on that too much.
Recommendation systems are an example of an application where we should have been able to anticipate the impact. There’s a kind of obvious implication in recommendation systems in general, and the various social media platforms have gone through having to confront this directly. The most well-known case study is YouTube’s recommendation engine, which for a while there, drew people very deliberately toward extremist views on any side. But because it’s based on its human behaviour, you’re attracted to what’s energizing, whether it’s positive or negative. And so the recommendation systems were basically creating extremes in the marketplace as a natural output of the “one plus one equals two” algorithm running behind the scenes. Optimizing engagement does not necessarily create the ideal world.
In short, when publishing, do you have an application? Then there’s no excuse not to think about the potential ethical implications, and to do that, well, you have to actually enlist experts in other fields. We actually need to be talking to sociologists and civic engineers and keep everybody involved in that specific application because there is no way I am going to be able to consider everything.
Secondly, there are misapplications. We talked about understanding the consequences of our work, but the other thing is communication: how you communicate your research to the public is at least as important as what you’re researching. For example, there was a Twitter flurry about one application that was marketed as being able to “show a trustworthiness rating based on a picture.” And we’ve been through this in history. You cannot judge characteristics like trustworthiness well, based on appearance, and of course you’ll never guess what kinds of biases work their way into those kinds of systems. So even though the paper itself, at various points, tried to make it clear it was “user-rated trustworthiness” — so reflecting what people think, rather than reality, when you say things like, “This is a trustworthy index” — people will say, “OK, then that means I can put a picture in and get a trustworthy rating out.” It’s so many steps from what it’s being called that it’s an irresponsible way of talking about the technology.
Faun: What I’m hearing, and tell me if I’m wrong, is that it’s very challenging to identify potential negative social impacts at a very abstract pre-application phase. But then there comes a point when you should be able to start anticipating impacts and misapplications, and being very careful about how you describe your work to the public. Where in the research process do you see that point occurring? Where is it appropriate to start asking researchers to start considering those outcomes?
Anna: We probably, as a field, have to enlist ethicists and sociologists to answer that question. We’re bad at gauging that. I think it would be interesting to study that very explicitly because it’s clear on the application end. I mean, when you do trials of machine learning systems with human participants, you have to go through the ethics approval for human experimentation, at least in a university setting. So obviously, at that point, there’s implications that are arising. But some of the stuff that we’re poking at — like what behaviours are created by different reward functions — we’re seeing the results of different optimization criteria. The fact that optimizing for click-through creates very extreme content actually comes out of the math. It’s literally doing what you ask it to do. So I think you can push that anticipation a little earlier.
It’s extra important the closer you are to directly impacting other people, or animals, or anything, the more you should be devoting at least some time to thinking about impacts. But I think also we need to have a more concerted effort of understanding what impacts look like, and the whole “build something/fail fast/break things” mentality is part of the problem — even though I’m a fan of agile development, and I really think you should get prototypes out there and get them tested and see the implications. But that’s a really important piece. You should be testing implications because there’s going to be a lot of unintended consequences once it’s out there in the real world.
For example, an exercise we do with clients sometimes is this: “Imagine I handed you a box that can, say, classify exactly the probability that a person is going to stay at your company for two years? I’m going to hand you that box. What are you going to do with it? How does that fit into your process?” And then once they’ve actually spent some time thinking about that, then what about if I say, “but it’s only accurate 80 percent of the time?” What are the implications of that? Or, “it’s accurate 100 percent of the time, but remember that it’s only telling you the probability they’ll stay at your company for two years, not that they’ll be a good employee, not that they’ll contribute positively to your culture.” It’s telling you that one little fact, which we hope is correlated with other things, but it’s often not.
So you really have to always be coming back full circle. And it goes back to our discussion earlier about linking the business value to the actual question. There is no perfect connection between the metrics we use and the actual things we care about. The things we care about are fuzzy and really, really hard to express. I know because I spent eight years trying to explain the concepts of “table” and “chair” to a computing agent repeatedly. So, yeah, forget explaining “value.” Everything is more complicated than we thought.
We have to do the same thing in the ethical sense. If we put a system out there, we need to get some people who are used to thinking about the impact of systems on society, make sure they’re in the loop, and then listen to recommendations from them. And all of this has been a critique of the researcher putting a little paragraph about the ethical implications of their paper. We’re bad at that, which should not absolve us from the responsibility for thinking about it and looking at it and watching how we communicate. But it does mean we need a concerted effort and we need to work together on it.
Faun: I really like the analogy you use with clients, the HR box. Before we close, is there anything you’d like to add that I didn’t think to ask you about?
Anna: A really, really essential message these days is don’t be afraid of technology. A lot of these things are going to be developed. We want to make sure that they are developed with the right intentions and with the right thought put into it. And like I said, that takes a concerted effort. We have to actually be working together on this. And that means give and take, in a lot of cases. Maybe sometimes you shouldn’t publish results because they’re too easily misinterpreted. Don’t be afraid of machine learning. Under the hood, it’s math, and you can understand it quite well without understanding math at all. So do read about the ethical implications and do read about how decision making is integrating it. And the final thing is we’re all contributing data to these systems. So, who we’re following on Twitter, what we’re watching, all of that is actually being fed back into the system about what is being shared. What’s being recommended? There’s a little piece of everybody contributing to this, so let’s all look at how we can do our part, trying to make the world a better place, even in the tiny things we do by choosing what to consume.

Anna Koop is Managing Director of Science at Amii, working to nurture productive relationships between industry and academia. Anna, whose research mainly focused on reinforcement learning, received her Master of Science in Computing Science under the supervision of Dr. Richard Sutton, one of the field’s pioneers. She is currently a PhD candidate working to develop algorithms for real-time learning in dynamic environments. Passionate about making science accessible for all, Anna has developed and taught a wide range of computing science classes through the University of Alberta.